Archived
The Ultimate Guide To Building Scalable Web Scrapers With Scrapy

The Ultimate Guide To Building Scalable Web Scrapers With Scrapy
The Ultimate Guide To Building Scalable Web Scrapers With Scrapy
Daniel Ni
2019-07-16T14:30:59+02:00
2019-07-17T12:35:59+00:00
Web scraping is a way to grab data from websites without needing access to APIs or the website’s database. You only need access to the site’s data — as long as your browser can access the data, you will be able to scrape it.
Realistically, most of the time you could just go through a website manually and grab the data ‘by hand’ using copy and paste, but in a lot of cases that would take you many hours of manual work, which could end up costing you a lot more than the data is worth, especially if you’ve hired someone to do the task for you. Why hire someone to work at 1–2 minutes per query when you can get a program to perform a query automatically every few seconds?
For example, let’s say that you wish to compile a list of the Oscar winners for best picture, along with their director, starring actors, release date, and run time. Using Google, you can see there are several sites that will list these movies by name, and maybe some additional information, but generally you’ll have to follow through with links to capture all the information you want.
Obviously, it would be impractical and time-consuming to go through every link from 1927 through to today and manually try to find the information through each page. With web scraping, we just need to find a website with pages that have all this information, and then point our program in the right direction with the right instructions.
In this tutorial, we will use Wikipedia as our website as it contains all the information we need and then use Scrapy on Python as a tool to scrape our information.
A few caveats before we begin:
Data scraping involves increasing the server load for the site that you’re scraping, which means a higher cost for the companies hosting the site and a lower quality experience for other users of that site. The quality of the server that is running the website, the amount of data you’re trying to obtain, and the rate at which you’re sending requests to the server will moderate the effect you have on the server. Keeping this in mind, we need to make sure that we stick to a few rules.
Most sites also have a file called robots.txt in their main directory. This file sets out rules for what directories sites do not want scrapers to access. A website’s Terms & Conditions page will usually let you know what their policy on data scraping is. For example, IMDB’s conditions page has the following clause:
Robots and Screen Scraping: You may not use data mining, robots, screen scraping, or similar data gathering and extraction tools on this site, except with our express-written consent as noted below.
Before we try to obtain a website’s data we should always check out the website’s terms and robots.txt to make sure we are obtaining legal data. When building our scrapers, we also need to make sure that we do not overwhelm a server with requests that it can’t handle.
Luckily, many websites recognize the need for users to obtain data, and they make the data available through APIs. If these are available, it’s usually a much easier experience to obtain data through the API than through scraping.
Wikipedia allows data scraping, as long as the bots aren’t going ‘way too fast’, as specified in their robots.txt. They also provide downloadable datasets so people can process the data on their own machines. If we go too fast, the servers will automatically block our IP, so we’ll implement timers in order to keep within their rules.
Getting Started, Installing Relevant Libraries Using Pip
First of all, to start off, let’s install Scrapy.
Windows
Install the latest version of Python from https://www.python.org/downloads/windows/
Note: Windows users will also need Microsoft Visual C++ 14.0, which you can grab from “Microsoft Visual C++ Build Tools” over here.
You’ll also want to make sure you have the latest version of pip.
In cmd.exe, type in:
python -m pip install --upgrade pip
pip install pypiwin32
pip install scrapy
This will install Scrapy and all the dependencies automatically.
Linux
First you’ll want to install all the dependencies:
In Terminal, enter:
sudo apt-get install python3 python3-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
Once that’s all installed, just type in:
pip install --upgrade pip
To make sure pip is updated, and then:
pip install scrapy
And it’s all done.
Mac
First you’ll need to make sure you have a c-compiler on your system. In Terminal, enter:
xcode-select --install
After that, install homebrew from https://brew.sh/.
Update your PATH variable so that homebrew packages are used before system packages:
echo "export PATH=/usr/local/bin:/usr/local/sbin:$PATH" >> ~/.bashrc
source ~/.bashrc
Install Python:
brew install python
And then make sure everything is updated:
brew update; brew upgrade python
After that’s done, just install Scrapy using pip:
pip install Scrapy
>
Overview Of Scrapy, How The Pieces Fit Together, Parsers, Spiders, Etc
You will be writing a script called a ‘Spider’ for Scrapy to run, but don’t worry, Scrapy spiders aren’t scary at all despite their name. The only similarity Scrapy spiders and real spiders have are that they like to crawl on the web.
Inside the spider is a class that you define that tells Scrapy what to do. For example, where to start crawling, the types of requests it makes, how to follow links on pages, and how it parses data. You can even add custom functions to process data as well, before outputting back into a file.
Writing Your First Spider, Write A Simple Spider To Allow For Hands-on Learning
To start our first spider, we need to first create a Scrapy project. To do this, enter this into your command line:
scrapy startproject oscars
This will create a folder with your project.
We’ll start with a basic spider. The following code is to be entered into a python script. Open a new python script in /oscars/spiders and name it oscars_spider.py
We’ll import Scrapy.
import scrapy
We then start defining our Spider class. First, we set the name and then the domains that the spider is allowed to scrape. Finally, we tell the spider where to start scraping from.
class OscarsSpider(scrapy.Spider):
name = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ['https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture']
Next, we need a function which will capture the information that we want. For now, we’ll just grab the page title. We use CSS to find the tag which carries the title text, and then we extract it. Finally, we return the information back to Scrapy to be logged or written to a file.
def parse(self, response):
data = {}
data['title'] = response.css('title::text').extract()
yield data
Now save the code in /oscars/spiders/oscars_spider.py
To run this spider, simply go to your command line and type:
scrapy crawl oscars
You should see an output like this:
2019-05-02 14:39:31 [scrapy.utils.log] INFO: Scrapy 1.6.0 started (bot: oscars)
...
2019-05-02 14:39:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2019-05-02 14:39:34 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2019-05-02 14:39:34 [scrapy.core.scraper] DEBUG: Scraped from
{'title': ['Academy Award for Best Picture - Wikipedia']}
2019-05-02 14:39:34 [scrapy.core.engine] INFO: Closing spider (finished)
2019-05-02 14:39:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 589,
'downloader/request_count': 2,
'downloader/request_method_count/GET': 2,
'downloader/response_bytes': 74517,
'downloader/response_count': 2,
'downloader/response_status_count/200': 2,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2019, 5, 2, 7, 39, 34, 264319),
'item_scraped_count': 1,
'log_count/DEBUG': 3,
'log_count/INFO': 9,
'response_received_count': 2,
'robotstxt/request_count': 1,
'robotstxt/response_count': 1,
'robotstxt/response_status_count/200': 1,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'start_time': datetime.datetime(2019, 5, 2, 7, 39, 31, 431535)}
2019-05-02 14:39:34 [scrapy.core.engine] INFO: Spider closed (finished)
Congratulations, you’ve built your first basic Scrapy scraper!
Full code:
import scrapy
class OscarsSpider(scrapy.Spider):
name = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
def parse(self, response):
data = {}
data['title'] = response.css('title::text').extract()
yield data
Obviously, we want it to do a little bit more, so let’s look into how to use Scrapy to parse data.
First, let’s get familiar with the Scrapy shell. The Scrapy shell can help you test your code to make sure that Scrapy is grabbing the data you want.
To access the shell, enter this into your command line:
scrapy shell “https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture”
This will basically open the page that you’ve directed it to and it will let you run single lines of code. For example, you can view the raw HTML of the page by typing in:
print(response.text)
Or open the page in your default browser by typing in:
view(response)
Our goal here is to find the code that contains the information that we want. For now, let’s try to grab the movie title names only.
The easiest way to find the code we need is by opening the page in our browser and inspecting the code. In this example, I am using Chrome DevTools. Just right-click on any movie title and select ‘inspect’:
Chrome DevTools window. (Large preview)
As you can see, the Oscar winners have a yellow background while the nominees have a plain background. There’s also a link to the article about the movie title, and the links for movies end in film). Now that we know this, we can use a CSS selector to grab the data. In the Scrapy shell, type in:
response.css(r"tr[style='background:#FAEB86'] a[href*='film)']").extract()
As you can see, you now have a list of all the Oscar Best Picture Winners!
> response.css(r"tr[style='background:#FAEB86'] a[href*='film']").extract()
['<a href="/wiki/Wings_(1927_film)" title="Wings (1927 film)">Wings</a>',
...
'<a href="/wiki/Green_Book_(film)" title="Green Book (film)">Green Book</a>', '<a href="/wiki/Jim_Burke_(film_producer)" title="Jim Burke (film producer)">Jim Burke</a>']
Going back to our main goal, we want a list of the Oscar winners for best picture, along with their director, starring actors, release date, and run time. To do this, we need Scrapy to grab data from each of those movie pages.
We’ll have to rewrite a few things and add a new function, but don’t worry, it’s pretty straightforward.
We’ll start by initiating the scraper the same way as before.
import scrapy, time
class OscarsSpider(scrapy.Spider):
name = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
But this time, two things will change. First, we’ll import time along with scrapy because we want to create a timer to restrict how fast the bot scrapes. Also, when we parse the pages the first time, we want to only get a list of the links to each title, so we can grab information off those pages instead.
def parse(self, response):
for href in response.css(r"tr[style='background:#FAEB86'] a[href*='film)']::attr(href)").extract():
url = response.urljoin(href)
print(url)
req = scrapy.Request(url, callback=self.parse_titles)
time.sleep(5)
yield req
Here we make a loop to look for every link on the page that ends in film) with the yellow background in it and then we join those links together into a list of URLs, which we will send to the function parse_titles to pass further. We also slip in a timer for it to only request pages every 5 seconds. Remember, we can use the Scrapy shell to test our response.css fields to make sure we’re getting the correct data!
def parse_titles(self, response):
for sel in response.css('html').extract():
data = {}
data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract()
data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract()
data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract()
data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract()
data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract()
yield data
The real work gets done in our parse_data function, where we create a dictionary called data and then fill each key with the information we want. Again, all these selectors were found using Chrome DevTools as demonstrated before and then tested with the Scrapy shell.
The final line returns the data dictionary back to Scrapy to store.
Complete code:
import scrapy, time
class OscarsSpider(scrapy.Spider):
name = "oscars"
allowed_domains = ["en.wikipedia.org"]
start_urls = ["https://en.wikipedia.org/wiki/Academy_Award_for_Best_Picture"]
def parse(self, response):
for href in response.css(r"tr[style='background:#FAEB86'] a[href*='film)']::attr(href)").extract():
url = response.urljoin(href)
print(url)
req = scrapy.Request(url, callback=self.parse_titles)
time.sleep(5)
yield req
def parse_titles(self, response):
for sel in response.css('html').extract():
data = {}
data['title'] = response.css(r"h1[id='firstHeading'] i::text").extract()
data['director'] = response.css(r"tr:contains('Directed by') a[href*='/wiki/']::text").extract()
data['starring'] = response.css(r"tr:contains('Starring') a[href*='/wiki/']::text").extract()
data['releasedate'] = response.css(r"tr:contains('Release date') li::text").extract()
data['runtime'] = response.css(r"tr:contains('Running time') td::text").extract()
yield data
Sometimes we will want to use proxies as websites will try to block our attempts at scraping.
To do this, we only need to change a few things. Using our example, in our def parse(), we need to change it to the following:
def parse(self, response):
for href in (r"tr[style='background:#FAEB86'] a[href*='film)']::attr(href)").extract()
:
url = response.urljoin(href)
print(url)
req = scrapy.Request(url, callback=self.parse_titles)
req.meta['proxy'] = "http://yourproxy.com:80"
yield req
This will route the requests through your proxy server.
Deployment And Logging, Show How To Actually Manage A Spider In Production
Now it is time to run our spider. To make Scrapy start scraping and then output to a CSV file, enter the following into your command prompt:
scrapy crawl oscars -o oscars.csv
You will see a large output, and after a couple of minutes, it will complete and you will have a CSV file sitting in your project folder.
Compiling Results, Show How To Use The Results Compiled In The Previous Steps
When you open the CSV file, you will see all the information we wanted (sorted out by columns with headings). It’s really that simple.
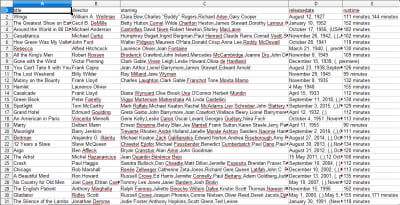
Oscar winning movies list and information. (Large preview)
With data scraping, we can obtain almost any custom dataset that we want, as long as the information is publicly available. What you want to do with this data is up to you. This skill is extremely useful for doing market research, keeping information on a website updated, and many other things.
It’s fairly easy to set up your own web scraper to obtain custom datasets on your own, however, always remember that there might be other ways to obtain the data that you need. Businesses invest a lot into providing the data that you want, so it’s only fair that we respect their terms and conditions.
Additional Resources For Learning More About Scrapy And Web Scraping In General
- The Official Scrapy Website
- Scrapy’s GitHub Page
- “The 10 Best Data Scraping Tools and Web Scraping Tools,” Scraper API
- “5 Tips For Web Scraping Without Getting Blocked or Blacklisted,” Scraper API
- Parsel, a Python library to use regular expressions to extract data from HTML.
(dm, yk, il)
From our sponsors: The Ultimate Guide To Building Scalable Web Scrapers With Scrapy